
1. Overview
As data workload continues to move up to the cloud, adopting cloud-native technology has become one of the biggest trends in the big data ecosystem. In the meantime, SPDB's 14th Five-Year Plan for Digital Technology also emphasizes cloud-native as a critical technology. Therefore, SPDB strives to innovate a cloud-native framework and apply it in their big data productions.
A traditional big data platform is an infrastructure that holds a huge amount of data and streamingly computes them. A typical big data platform includes components such as Hadoop, Spark, Flume, Flink, Kafka, etc. The containerization and orchestration of those components give birth to Cloud-Native Big Data Platforms.
After studying mainstream big data platforms, such as Cloudera CDP, and fully understanding the advantages and challenges of adopting cloud-native workflows, SPDB recognized that storage technology is the key to achieving success in building a cloud-native big data platform. Therefore, SPDB works with partners on the cloud-native storage project Piraeus Datastore and tested its functionalities in various big data scenarios.
2. Piraeus Storage System in Cloud-Native Big Data Platform
Containerized big data services have a lot of stateful applications that require attaching and mounting Kubernetes persistent volumes (a.k.a PVs). Piraeus fulfills different PV specs by providing enterprise features such as high-performance replicas, efficient pool management and fast failover.
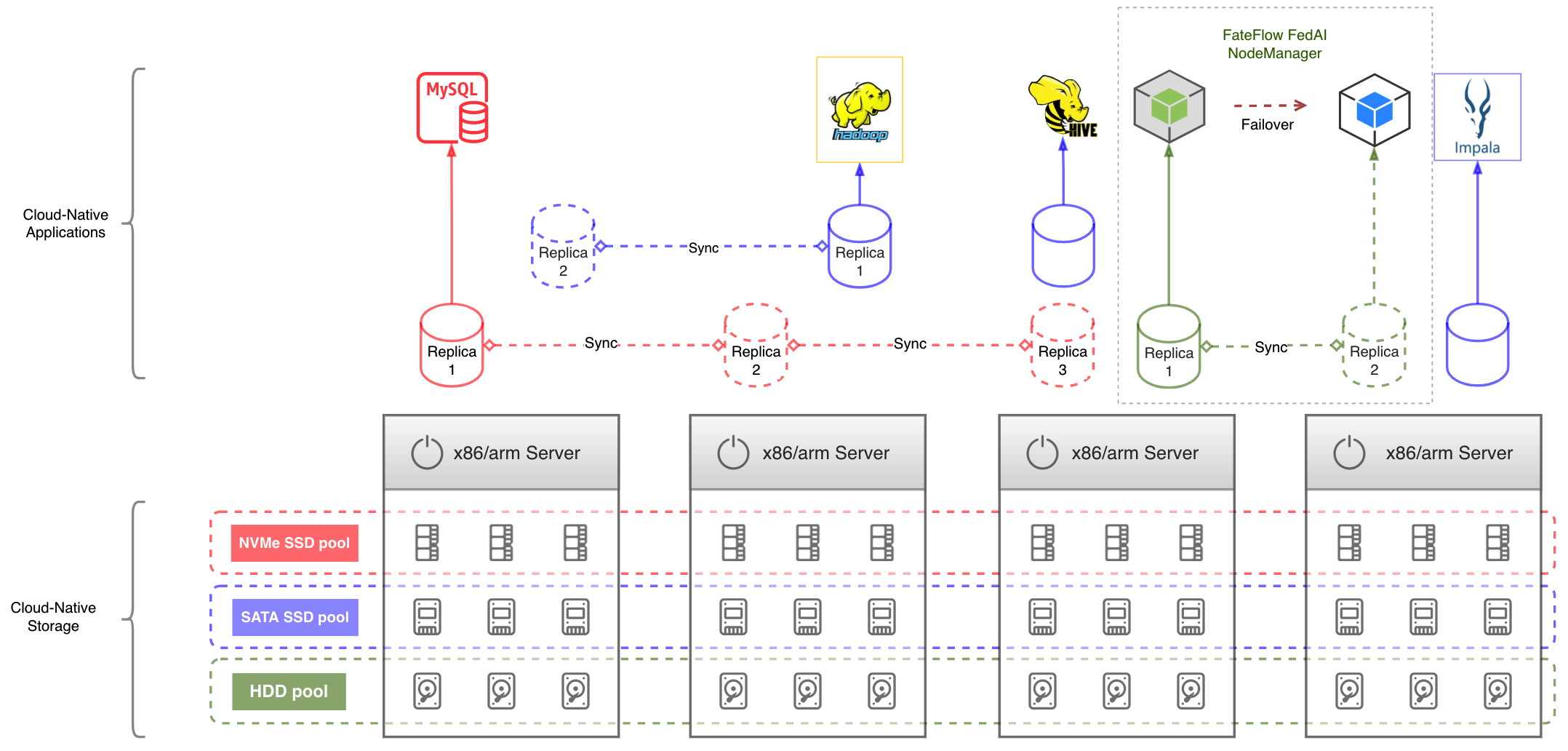
2.1. High-Performance Replicas
MySQL database, Hadoop name node, and FedAI node-managers all have data that requires both high availability and high performance. Piraeus provides volumes with dual or triple replicas, by which data are synchronized between different nodes to avoid any single point of failure (SPOF).
2.2. Efficient Pool Management
Contemporary enterprise servers are typically equipped with physical hard drives, faster SATA SSD drives and even faster NVMe SSD drives. Piraeus provisions volumes with various performance specs by grouping different storage media in separated storage pools. For example, in the below chart, MySQL uses PV from NVMe SSD pool (marked by red); Hadoop name node uses PV from SATA SSD pool (marked by blue); Federated AI node0manager uses PV from physical hard drive pool (marked by green).
2.3. Fast Failover
When a Kubernetes node has hardware failures, Kubernetes will reschedule the pods on it to another healthy node. Piraeus operates a smart failover controller which intervenes the rescheduling pipeline to make sure that the pod land on a node with the replicated data. By default, it takes at least 12 minutes for Kubernetes to reschedule a stateful pod. The failover controller may shorten that time to 1 minute or even 30 seconds.
3. Cloud-Native Federated AI
As one of the first major banks that employ Federated AI, SPDB has developed a secure, highly-available, and high-performance cloud-native federated AI platform from the open-source framework FATE. The new platform enables rapid integration and application of federated learning technology into a wide range of banking businesses, provides full-lifecycle solutions for marketing, risk control, customer management, and operational decision-making, breaks down barriers to data cooperation, and facilitates business scenarios with partners in various fields. The innovation helps SPDB expands its business scale.
To ensure the entire federated learning platform can provide high-performance secure computing in a cloud-native environment, the node-manager has the following data requirements:
- Mount POSIX file system for data access
- Access the data anywhere in the cluster
- No single point of failure (SPOF)
- High throughput and low latency
SPDB's engineers first used the NFS service from an external enterprise-grade NAS storage to mount the data to the container of the computing storage engine, in the form of Kubernetes persistent volume (PV). Although this can meet the first three requirements, the performance was very bad. After that, they used the local path for mounting, which solved the performance problem but created a single point of failure. Besides, the mounted local path prevents the container from migrating to any new node.
After much research and experiments, SPDB's engineers adopted Piraeus cloud native storage to meet the above four requirements. Piraeus data volumes are block devices, mounted natively using ext4 or xfs file systems. Piraeus Kubernetes-CSI driver and DRBD Transport remote mount technology enable containers to access data volumes from any node in the cluster. Piraeus multi-replica volumes use DRBD synchronous replication technology to ensure high availability while providing high throughput and low latency that are comparable to local disks.
After successfully using Piraeus to support node-managers, they also configured their MySQL containers to mount a Piraeus replica volumes, which also achieved very satisfying results.
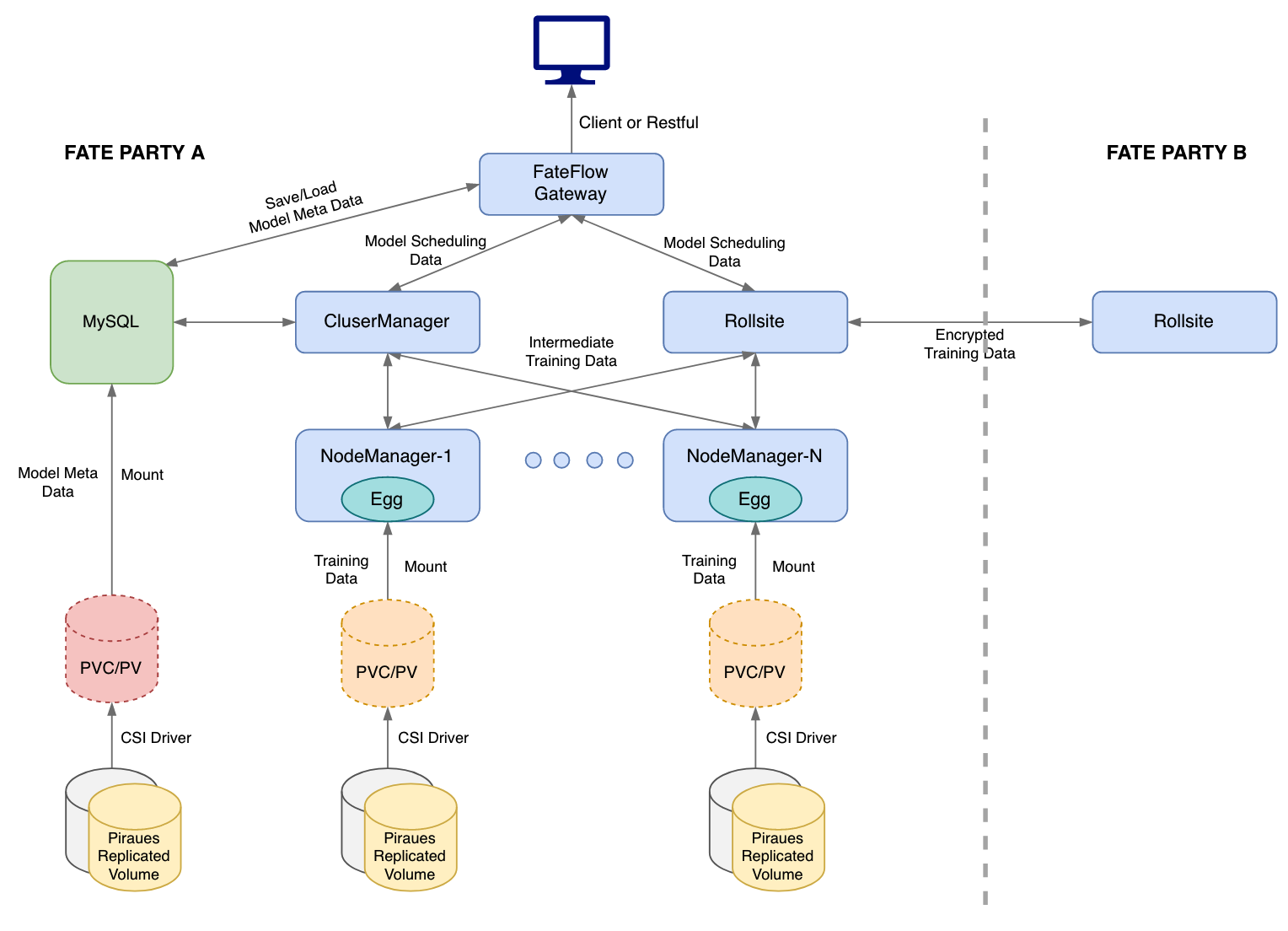
4. Workflow
The PVs for Eggroll NodeManager and MySQL are provided by Piraeus.
5. Performance Test
After replacing NFS PV with Piraeus 2-replica volume, Federated AI workloads gain a considerable performance boost.
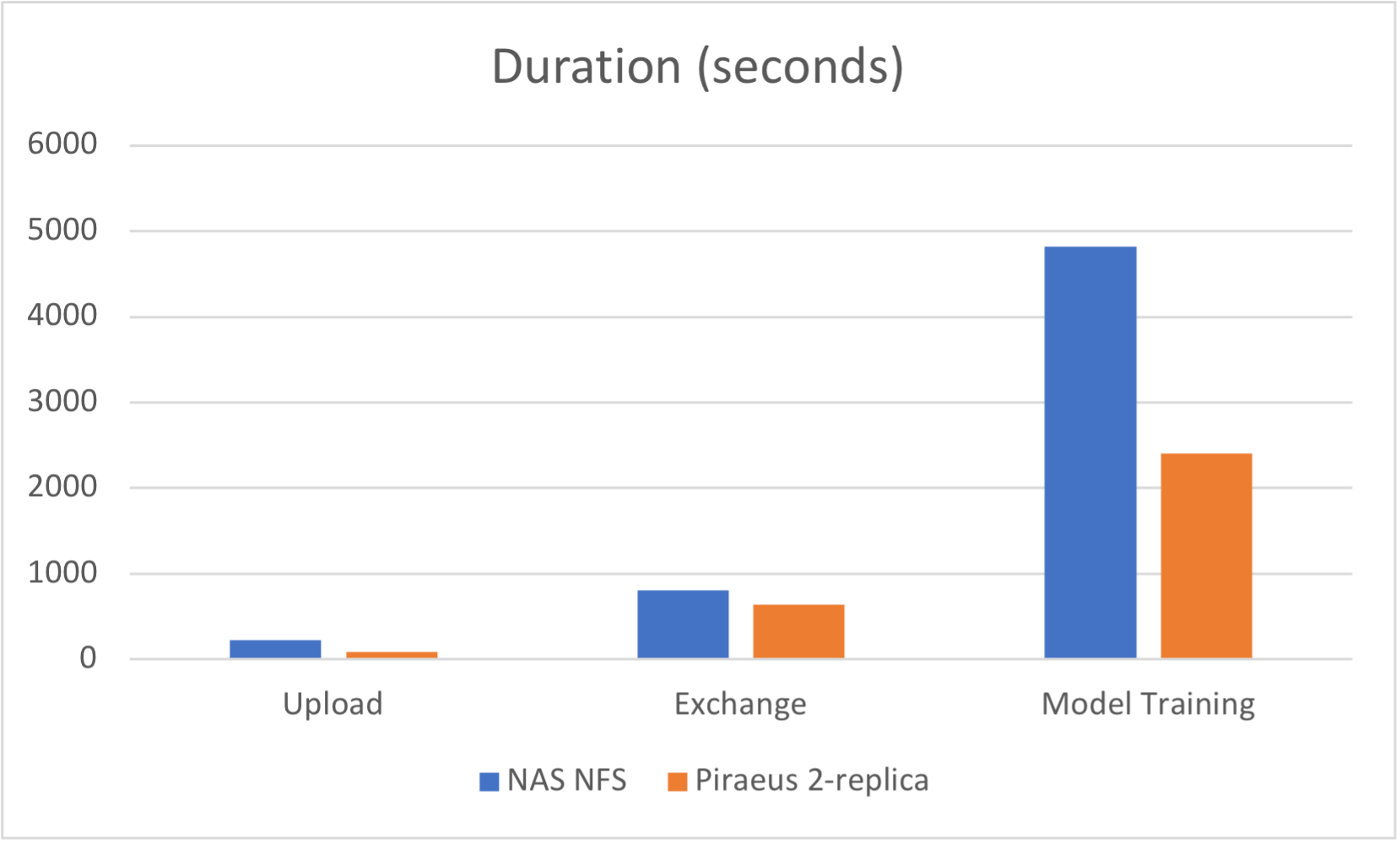
| Test/Storage | NAS NFS | Piraeus 2-replica |
|---|---|---|
| Upload (40w) | 3m50s | 1m25s |
| Exchange (40w vs 40w) | 13m31s | 10m43s |
| Model Traning | 80m23s | 40m2s |
The above tests are not results per the same hardware. The NFS comes from an enterprise-grade NAS storage server; whereas the Piraeus uses the virtual machines' local virtual disks in its storage pools, which means the NFS backend hardware performance is much higher than that of the Piraeus. Therefore, if the Piraeus backend uses NAS-equivalent hardware, the performance will be even better.
6. Challenges in cloud-native big data platforms
Kubernetes CSI Interface Standard
Cloud native storage must support the Kubernetes CSI interface standard. The Piraeus open source project has been following each technical iteration from CSI community, developing a full set of "sidecar" containers that implement the features described by the CSI framework, on top of which it has developed advanced features such as HA failover and NFS Export.
Data Affinity and Intelligent Scheduling
Cloud-native storage needs to support the data affinity (VolumeNodeAffinity) which defines on which node a pod can access its data. Piraeus implements VolumeNodeAffinity at the CSI level and provides an advanced scheduler which ensures a container, during its lifecycle, can be scheduled to a node closest to the data.
High availability of data
Cloud-native storage needs to ensure that data has no single point of failure. The data volume of Piraeus employs DRBD, a mature data replication technology, which provides high availability of double and triple replicas, and also has the ability to remotely attach the device. Together with the intelligent scheduler, the container can alway run on the nodes where the replica is located.
Fast failover
Kubernetes reschedules the containers when the Kubernetes node is powered off or the local data is corrupted. Piraeus' intelligent HA controller can intervene the container scheduling process (pipeline) to ensure that containers are scheduled to nodes with data replicas, and at the same time shorten the scheduling time as much as possible: by default, the container rescheduling takes 12 minutes or more, Piraeus can cut it down to 1 minute or even 30 seconds
7. Conclusion
Big data technology and cloud-native technology, one is a cornerstone technology in the field of data processing, and the other is an emerging technology that has revolutionized business orchestration in recent years. The two are constantly growing and evolving in their respective ecosystems. Now, they interact and integrate through a common storage technology stack. Therefore, SPDB will continue to explore cloud-native storage technology in the future, study the comprehensive cloud-native Hadoop ecosystem, and explore cloud-native projects, computing engines, scheduling systems and other application solutions which can help more big data applications ride on the wave of cloud-native transformation that further empowers the financial industry.